By: Emmanuel Letouzé
Send to a friend
The details you provide on this page will not be used to send unsolicited email, and will not be sold to a 3rd party. See privacy policy.
What is big data, and could it transform development policy? Emmanuel Letouzé takes a close look at this emerging field.
In just a few years ‘big data’ have affected industries and activities from marketing and advertising to intelligence gathering and law enforcement, stirring much excitement and scepticism. With policymaking increasingly looking like big data’s next frontier, is this phenomenon — what one expert, Andreas Weigend, is calling the ’new oil’ that needs to be refined — poised to be a blessing or a curse for human development and social progress? [1,2]
Optimists are calling it a revolution that will change, mostly for the better, “how we live, think and work” (see below for a video of The Economist’s Kenneth Cukier). Some World Bank officials have even expressed the hope that “Africa’s statistical tragedy” — that is, the dearth of reliable official statistics in some of the world’s poorest places — may be partly fixed by big data.[3,4] But sceptics and critics have been more circumspect, and some plainly antagonistic — referring to big data as a big ruse, a big hype, a big risk as well as, of course, ‘big brother’, in the wake of the revelations by former US National Security Agency contractor Edward Snowden.
Gaining ground
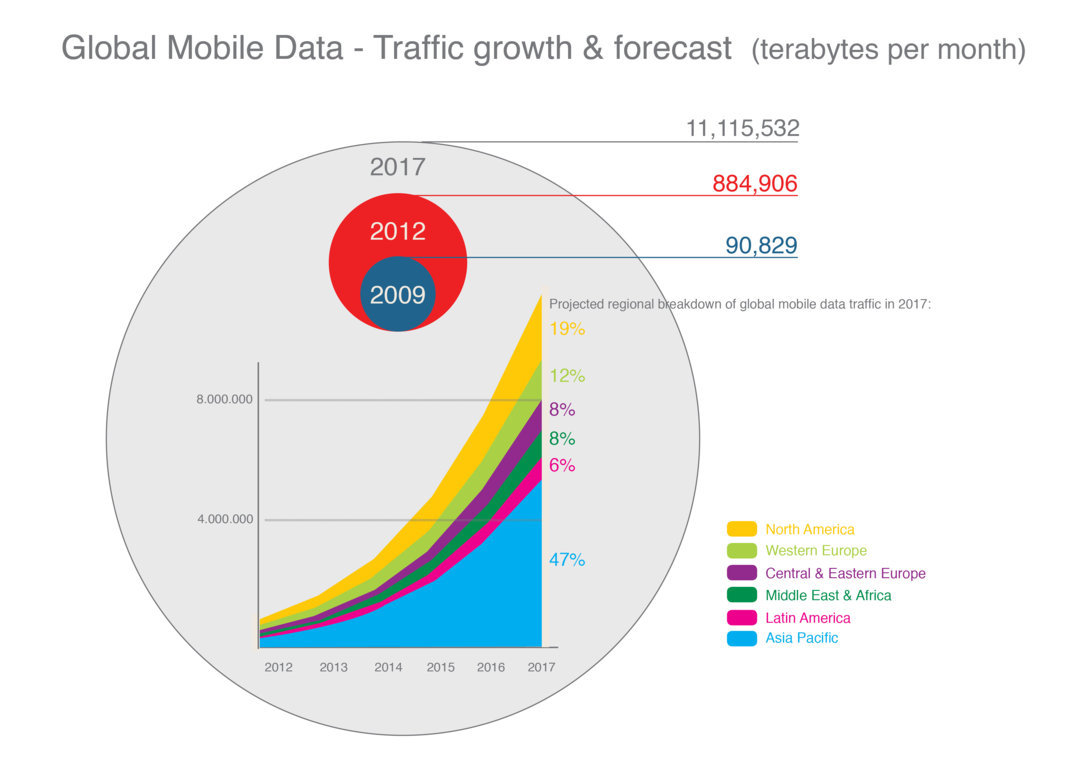
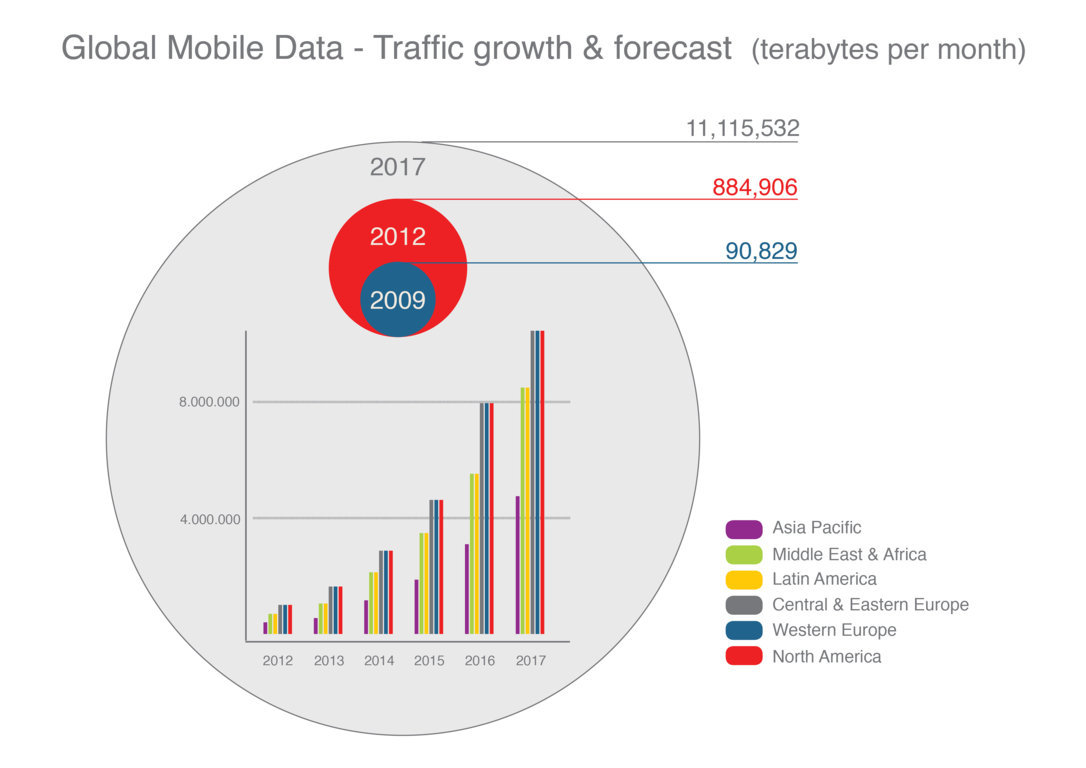
Big data, especially as applied to development and public policy issues, is in its intellectual and operational infancy. Joe Hellerstein, computer scientist at the University of California, Berkeley, United States, made an early mention of an upcoming “Industrial Revolution of data” in November 2008, while The Economist talked about a “data deluge” in early 2010.[5,6] ‘Big data’ itself became a mainstream term only a couple of years ago. Google searches (see Figure1) are one metric that shows this: the number of searches that include the term did not take off until 2011–12. In those two years, four major reports were published: by the UN Global Pulse, the World Economic Forum, the McKinsey Global Institute and Danah Boyd and Kate Crawford, researchers at Microsoft and academic institutions. [7-10]
Over the past three years, publications and initiatives about ‘big data for development’ or ‘data science for social good’ have become a source of big data themselves.
Of course, the big data buzz could just be a bubble, or just hype: as some observers point out, automated analysis of large datasets is not new. So what is?
What is big data?
There is no single agreed definition of big data. For one, it is data generated through our increasing use of digital devices and web-supported tools and platforms in our daily lives. In any given minute, hundreds of millions of individuals across the globe use some of the world’s seven to eight billion mobile phones to make a call, send a text message or an email. Or they may wire money, buy a book, search online, pay for a meal with a credit card, update their Facebook status, send tweets, upload videos to YouTube, publish a blog post and so on. Each of these actions leaves a digital trace. Added up, this digital information makes up the bulk of big data. Each year since 2012, well over 1.2 zettabytes of data has been produced — 1021 bytes, enough to fill 80 billion 16GB iPhones (which would circle the earth more than 100 times). (Table 1) And the volume of these data is growing fast. [11] So volume, velocity and variety are the three ‘Vs’ that characterise big data, with the value that could be extracted from them often added as a fourth V.
Table 1— Data ‘inflation’
| Unit | Size | What it means |
|---|---|---|
| Bit (b) | 1 or 0 | Short for “binary digit”, after the binary code (1 or 0) computers use to store and process data—including text, numbers, images, videos, etc. |
| Byte (B) | 8 bits | Enough information to create a number or an English letter in computer code. It is the basic unit of computing. |
| Kilobyte (KB) | 1,000, or 210, bytes | From “thousand” in Greek. One page of typed text is 2KB. |
| Megabyte (MB) | 1,000KB, or 220, bytes | From “large” in Greek. The MP3 file of a typical song is about 4MB. |
| Gigabytes (GB) | 1,000MB, or 230, bytes | From “giant” in Greek. A two-hour film can be compressed into 1-2GB. A 1GB text file contains over 1 billion characters, or roughly 290 copies of Shakespeare’s complete works. |
| Terabyte (TB) | 1,000GB, or 240, bytes | From “monster” in Greek. All the catalogued books in America’s Library of Congress total 15TB. All the tweets sent before the end of 2013 would approximately fill an 18.5TB text file. Printing such a file (at a rate of 15 A4-sized pages per minute) would take over 1200 years. |
| Petabyte (PB) | 1,000TB, or 250, bytes | The NSA is reportedly analyzing 1.6 per cent of global Internet traffic, or about 30PB, per day. Continuously playing 30PB of music would take over 60,000 years, which corresponds to the time that has elapsed since the first Homo Sapiens left Africa. |
| Exabyte (EB) | 1,000PB, or 260, bytes | 1EB of data corresponds to the storage capacity of 33,554,432 iPhone 5 devices with a 32GB memory. By 2018, the total volume of monthly mobile data traffic is forecast to be about half of an EB. If this volume of data were stored on 32GB iPhone 5 devices stacked one on top of the other, the pile would be over 283 times the height of the Empire State Building. |
| Zettabyte (ZB) | 1,000EB, or 270, bytes | It is estimated that in 2013, humanity generated 4-5ZB of data, which exceeds the quantity of data in 46 trillion print issues of The Economist. If that many magazines were laid out sheet by sheet on the ground, they would cover the total land surface area of the Earth. |
| Yottabyte (YB) | 1,000ZB, or 280, bytes | The contents of one human’s genetic code can be stored in less than 1.5GB, meaning that 1YB of storage could contain the genome of over 800 trillion people, or roughly that of 100,000 times the entire world population. |
And much as a population with a sudden outburst of fertility gets both larger and younger, the proportion of digital data produced recently is growing ever faster — up to 90 per cent of the world’s data was created over just two years (2010–2012), according to one much cited account. [12]
Data types
Big data come in different types. One kind is small pieces of ‘hard’ data — numbers or facts, for example — described by Alex ‘Sandy’ Pentland, a professor at the Massachusetts Institute of Technology, United States, as “digital breadcrumbs”. [13] They are said to be ‘structured’ because they make up datasets of variables that can be easily tagged, categorized, and organized (in columns and rows for instance) for systematic analysis. One example is Call Detail Records (CDRs) collected by mobile phone operators (Table 2). CDRs are metadata (data about data) that capture subscribers’ use of their cell-phones — including an identification code and, at a minimum, the location of the phone tower that routed the call for both caller and receiver — and the time and duration of call. Large operators collect over six billion CDRs per day. [14] (Figure 2).
Table 2. Data contained in a CDR
| Variable | Data |
|---|---|
| Caller ID | X76VG588RLPQ |
| Caller ID tower location | 2°24' 22.14" , 35°49' 56.54 |
| Recipient phone number | A81UTC93KK52A81UTC93KK52 |
| Recipient cell tower location | 3°26' 30.47", 31°12' 18:01" |
| Call time | 3013-11-07T15:15:00 |
| Call duration | 01:12:02 |
A second kind of big data are videos, documents, blog posts and other social media content. Most of these data are ‘unstructured’ — and so harder to analyse. They differ from ‘breadcrumbs’ in that they are subject to their authors’ editorial choices and, being subjective, may paint a deceiving picture. For example, you might blog that you are boycotting a certain product, but your credit card statement may reveal a different preference based on actual purchases.
A third kind of big data is gathered remotely by digital sensors and reflects human actions. These might be ‘smart meters’ installed in homes to record electricity consumption, or satellite imagery that can pick up physical information such as vegetation cover as an indicator of deforestation. [15]
Some consider the universe of big data to be much wider — including administrative records, price or weather data, for instance, or books that have been previously digitized —which, taken collectively, may constitute a fourth kind.
 Click here to enlarge
Click here to enlarge Defining features
But the bulk of big data is machine-readable, generated about and by people — some combination of the types mentioned above. These data were unavailable 10 years ago, before the age of Facebook or the explosion of mobile phone use — and they stem from powerful technological and societal changes.
Big data’s main novelty is that they come from electronic sources and end up in databases whose primary purpose is not statistical inference.[16] In other words, they were not collected or sampled with the explicit intention of drawing conclusions from them. This also makes putting big data to use challenging.
So the term big data may be a misleading misnomer: size isn’t their defining feature. For example, an Excel spreadsheet with CDRs may not be a big file; the entire World Bank Development Indicators database is a big file — but the latter results from fully controlled processes, including surveys and statistical imputations undertaken by official bodies. The difference is primarily qualitative — it’s in the kinds of information contained in the data and the way these are generated.
To add an extra layer of complexity, “Big Data is not about the data”, as Harvard University professor Gary King puts it. [17] It’s about big data analytics, which broadly refers to improvements in computing power and analytical capacities — such as statistical machine-learning and algorithms that are able to look for and unveil patterns and trends in vast amounts of complex data. This is the second feature of big data: the tools and methods, hardware and software now available to analyse digital data.
A third, less discussed but important property of big data is that it has become is a ‘movement’.[18] And that movement is increasingly attracting multidisciplinary teams of social and computer scientists with a “mindset to turn mess into meaning”, as data scientist Andreas Weigend puts it — in essence, defining big data as a movement to turn data into decision making. [2] Statements such as this have renewed interest in the prospects and promise of ‘data-driven’ or ‘evidence-based’ policymaking — although there are technical, technological, commercial and political implications that are far from trivial.
How exactly can big data — new kinds of data, new capacities to analyse it, with new intentions — affect societies? And what explains the buzz it has created?
The promise stems from two aspects: supply of ever-more data, and demand for better, faster and cheaper information — in other words there is both a push for and a pull towards big data.
Data demand
People are frustrated with the current tools and systems available for decision-making. For instance, a good indicator of a region’s poverty or underdevelopment is a lack of poverty or development data. [19]
Some countries (most of them with a recent history of conflict) haven’t had a census in four decades or more. Their population size, structure and distribution is essentially anyone’s guess. Even though official figures exist, they are often based on incomplete data. [20] Poor data also mean that some countries’ official GDP figures get an overnight boost — of 40 per cent for Ghana in 2010 or 60 per cent for Nigeria in 2014 — when changes in the structure of their economies, such as the rise of the technology sector, are finally taken into account. [21-22]
This lack of reliable data has presided over the recent UN call for a ‘Data Revolution’. The basic rationale is that, in the age of big data, economies should be steered by policymakers relying on better navigation instruments and indicators that let them design and implement more agile and better targeted policies and programmes. Big data has even been said to hold the potential for national statistical systems in data-poor areas to ‘leapfrog’ ahead, much as many poor countries skipped the landline phase to jump straight into the mobile phone era. [4]
Supplying new knowledge
The appeal of potentially leaping ahead is also shaped by the ‘supply side’ of big data. There is early practical evidence and a growing body of work on big data’s novel potential to understand and affect human populations and processes.
For example, big data has been used to track inflation online, estimate and predict changes in GDP in near real-time, monitor traffic or even a dengue outbreak. [23-26] Monitoring social media data to analyse people’s sentiments is opening new ways to measure welfare, while email and Twitter data could be used to study internal and international migration. [25,27] And an especially rich and growing academic literature is using CDRs to study migration patterns, socioeconomic levels and malaria spread, among others.
Guidance for analysing big data, published by UN Global Pulse, has focused on four fields: disaster response, public health, poverty and socioeconomic levels, and human mobility and transportation (See Box 1). [28]
Box 1: Mobile phone data analysis examples, based on UN Global Pulse’s primer and the 2013 World Disaster Report |
|
Data on mobile money transfers in the aftermath of the 2008 earthquake in Rwanda was used to analyse the timing, magnitude, and motivation of donations to affected communities — revealing notably that transfers were more likely to benefit wealthier individuals. [29] CDR analysis has been used to study infectious disease spread and control in an urban slum in Kibera, Kenya. An especially promising avenue is using CDRs to predict socio-economic levels. This is done by overlaying and matching CDR-based indicators (such as average call volumes in an area) with known socioeconomic variables (such as income levels) to build statistical models able to ‘predict’ patterns and trends (see Figure 3).
 Click to enlarge Click to enlargeFor human mobility and transportation, CDRs from Côte d’Ivoire, made available by Orange under the umbrella of a D4D (Data for Development) challenge, helped model bus routes in Abidjan and show that travel time could be reduced by 10 per cent. This sort of analysis uses: Real-time traffic information. For instance, Google Traffic Alerts provide information to consumers on their daily commute using a mix of data sources — some public (such as construction schedules), some private (such as telecom companies tracking individual user devices to calculate time to work) and some passively-generated (for example, a cluster of calls made from a similar location might indicate a traffic jam). Enhanced understanding of travel behaviour. This requires matching together travel data derived from mobile phone use with other socio-economic data to reveal a pattern of preferences in travel behaviour (as opposed to stated preferences, derived from surveys). As an example, in the UK, East Coast Trains used data from Telefonica to better understand customer behaviour on the London to Edinburgh route.
|
Meanwhile, various other authors have proposed how big data could benefit development. The UN Global Pulse distinguished the ‘early warning’ uses from ‘real-time awareness’, or from ‘real-time monitoring’ of the impact of a policy. Others contrast its descriptive function (such as a real-time map) from predictive and diagnostic functions (See Table 3). [7,30]
Table 3 Actual and potential uses of big data for development
| Applications | Explanation | Examples | Comments and caveats |
|---|---|---|---|
UN GLOBAL PULSE TAXONOMY |
|||
| 1. Early warning | Big data can document and convey what is happening | This application is quite similar to the ‘real-time awareness’ application — although it is less ambitious in its objectives. Any infographic, including maps, that renders vast amounts of data legible to the reader is an example of a descriptive application | Describing data always implies making choices and assumptions — about what and how data are displayed — that need to be made explicit and understood; it is well known that even bar graphs and maps can be misleading |
| 2. Real-time awareness | Big data could give a sense of what is likely to happen, regardless of why | One kind of ‘prediction’ refers to what may happen next — the predictive policing mentioned above is one example. Another kind refers to predicting prevailing conditions through big data — as in the cases of socioeconomic levels using CDRs in Latin America and Ivory Coast | Similar comments as those made for the ‘early-warning’ and ‘real-time awareness’ applications apply |
| 3.Real-time feedback | Big Data might shed light on why things may happen and what could be done about it | So far there have been next to no clear-cut examples of this application in development contexts. The example of CDR data used to show that bus routes in Abidjan could be ‘optimized’ falls closest to a case where the analysis identifies causal links and can shape policy | Most comments about ‘real-time feedback’ application apply. Strictly speaking, an example of the diagnostics application would require being able to assign causality. The prescriptive application works best in theory when supported by feedback systems and loops on the effect of policy actions |
ALTERNATIVE TAXONOMY |
|||
| 1. Descriptive | Early detection of anomalies in how populations use digital devices and services can enable faster response in times of crisis | Predictive policing, based upon the notion that analysis of historical data can reveal certain combinations of factors associated with greater likelihood of increased criminality in a given area; it can be used to allocate police resources. Google Flu trends is another example, where searches for particular terms (“runny nose”, “itchy eyes”) are analyzed to detect the onset of the flu season — although its accuracy is debated | This application assumes that certain regularities in human behaviors can be observed and modeled. Key challenges for policy include the tendency of most malfunction-detection systems and forecasting models to over-predict — i.e. to have a higher prevalence of ‘false positives’ |
| 2. Predictive | Big data can paint a fine-grained and current representation of reality which can inform the design and targeting of programs and policies | Using data released by Orange, researchers found a high degree of association between social networks and language distribution in Ivory Coast — suggesting that such data may provide information about language communities in countries where it is unavailable | The appeal and underlying argument for this application is the notion that big data may be a substitute for bad or scarce data; however models that show high correlations between ‘big data-based’ and ‘traditional’ indicators often require the availability of the latter to be trained and built. ‘Real-time’ here means using high frequency digital data to get a picture of reality at any given time |
| 3. Prescriptive, or diagnostic | The ability to monitor a population in real time makes it possible to understand where policies and programs are failing, and make the necessary adjustments | Private corporations already use big data analytics. For development, this might include analysing the impact of a policy action — e.g. the introduction of new traffic regulations — in real-time. | Although appealing, few (if any) actual examples of this application exist; a challenge is making sure that any observed change can be attributed to the intervention or ‘treatment’. However high-frequency data can also contain ‘natural experiments’ — such as a sudden drop in online prices of a given good — that can be leveraged to infer causality |
Risks and challenges
Of course, big data’s promise has been met with warnings about its perils. The risks, challenges and more generally the hard questions were articulated as ‘early’ as 2011. [10]
Perhaps the most severe risks — and most urgent avenues for research and debate — are to individual rights, privacy, identity, and security. In addition to the obvious intrusion of surveillance activities and issues around their legality and legitimacy, there are important questions about ‘data anonymization’: what it means and its limits. A study of movie rentals showed that even ‘anonymized’ data could be ‘de-anonymized’ — linked to a known individual by correlating rental dates of as few as three movies with the dates of posts on an online movie platform. [31] Other research has found that CDRs that record location and time, even when free of any individual identifier could be re-individualized. In that case, four data points were theoretically sufficient to uniquely single out individuals out of the whole dataset with 95 per cent accuracy. [32]
Critics also point to the risks associated with basing decisions on biased data or dubious analyses (sometimes called threats to both external and internal validity). If policymakers come to believe that ‘the data don’t lie’, such risks could be especially worrisome. Box 2 gives some examples.
Box:
Box 2. Big data – risks to drawing valid conclusions |
|
A key challenge in big data is that the people generating it have selected themselves as data generators through their activity. In technical terms this is a ‘selection bias’ and it means that analysis of big data is likely to yield a different result from a traditional survey (or poll), which would seek out a representative cross section of the population. For example, trying to answer the question “do people in country A prefer rice or chips?” by mining data on Twitter would be biased in favour of young people’s preferences as they make up more of Twitter’s users. So analyses based on big data may lack ‘external validity’, although it is possible that individuals that differ in almost all respects may have similar preferences and display identical behaviors (young people may have the same preferences as older people). Another risk comes from analyses that are flawed because they lack ‘internal validity’. For instance, a sharp drop in the volume of CDRs from an area might be interpreted, based on past events, as heralding a looming conflict. But it could actually be caused by something different, such as a mobile phone tower having gone down in the area. |
Another risk is that analyses based on big data will focus too much on correlation and prediction — at the expense of cause, diagnostics or inference, without which policy is essentially blind. A good example is ‘predictive policing’. Since about 2010, police and law enforcement forces in some US and UK cities have crunched data to assess the likelihood of increased crime in certain areas, predicting rises based on historical patterns. Forces dispatch their resources accordingly, and this has reduced crime in most cases. [33] However, unless there is knowledge of why crime is rising it’s not possible to put in place preventive policy that tackles the root causes or contributing factors. [34]
Yet another big risk that has not received the attention it merits is big data’s potential to create a ‘new digital divide’ that may widen rather than close existing gaps in income and power worldwide. [35] One of the ‘three paradoxes’ of big data is that because it requires analytical capacities and access to data that only a fraction of institutions, corporations and individuals have, the data revolution may disempower the very communities and countries it promises to serve. [36] People with the most data and capacities would be in the best position to exploit big data for economic advantage, even as they claim to use them to benefit others.
A related and basic challenge is that of putting the data to use. All discussions about the ‘data revolution’ assume that ‘data matter’; that poor data are partly to blame for poor policies. But history has shown that lack of data or information has historically played only a marginal role in the decisions leading to bad policies and poor outcomes. And a blind ‘algorithmic’ future may undercut the very processes that are meant to ensure that the way data are turned into decisions is subject to democratic oversight.
Big future
But since the growth in data production is highly unlikely to abate, the ‘big data bubble’ is similarly unlikely to burst in the near future. The world can expect more papers and controversies about big data’s potential and perils for development. The future of big data will likely be shaped by three main strands: of academic research, legal and technical frameworks for ethical use of data, and larger societal demands for greater accountability.
Research will continue to examine whether and how methodological and scientific frontiers can be pushed, especially in two areas: drawing stronger inferences, and measuring and correcting sample biases.
Policy debate will develop frameworks and standards — normative, legal and technical — for collecting, storing and sharing big data. These developments fall under the umbrella term ‘ethics of big data’. [37,38] Technical advances will help, for example by injecting ‘noise’ in datasets to make re-identification of the individuals represented in them more difficult. But a comprehensive approach to the ethics of big data would ideally encompass other humanistic considerations such as privacy and equality, and champion data literacy. [39]
A third influence on the future of big data will be how it engages and evolves alongside the ‘open’ data movement and its underlying social drivers — where ‘open data’ refers to data that is easily accessible, machine-readable, accessible for free or at negligible cost, and with minimal limitations on its use, transformation, and distribution. (See Figure 4] [40]

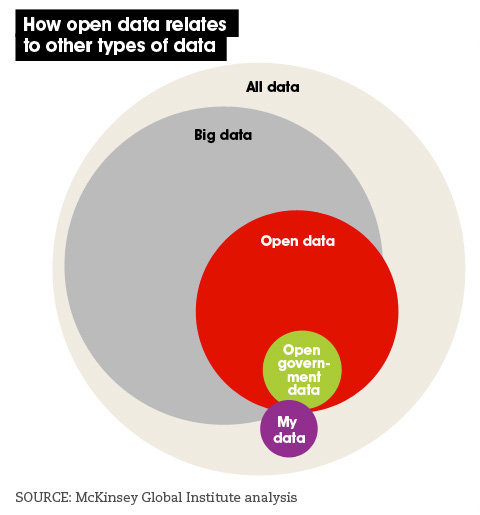 Click on the image above to enlarge
Click on the image above to enlargeFor the foreseeable future, the big data and open data movements will be the two main pillars of a larger ‘data revolution’. Both rise against a background of increased public demand for more openness, agility, transparency and accountability for public data and actions. The political overtones — so easily forgotten — are clear. And so a ‘true’ big data revolution should be one where data can be leveraged to change power structures and decision-making processes, not just create insights. [41]
Emmanuel Letouzé is a PhD Candidate at the University of California, Berkeley, a fellow at the Harvard Humanitarian Initiative, a visiting scholar at the MIT Media Lab and a research associate at the Overseas Development Institute. He can be contacted at [email protected] and on Twitter @Data4Dev.
| Definitions | |
|---|---|
| Algorithms (and algorithmic future) | in mathematics and computer science, an algorithm is a series of predefined instructions or rules written in a programming language designed to tell a computer how to sequentially solve a recurrent problem through calculations and data processing. The use of algorithms for decision-making has grown in several sectors and services such as policing and banking. This has led to hopes — and worries — about the advent of an ‘algorithmic future’ where algorithms may replace human functions, or even become an instrument for repression. |
| Big data | an umbrella term that, simply put, stands for one or more of three trends: the growing volume of digital data generated daily as a by-product of people’s use of digital devices; the new technologies, tools and methods available to analyse large data sets that are not designed for analysis; and the intention to extract policymaking insights from these data and tools. |
| Call Detail Records (CDRs) | the technical name for mobile phone data recorded by all telecom operators. CDRs contain information about the locations of those sending and receiving calls or text messages through operators’ networks, as well as data on time and duration. |
| Data revolution | a common term in development discourse since the High-Level Panel of Eminent Persons on the Post-2015 Development Agenda called for a ‘data revolution’ to “strengthen data and statistics for accountability and decision-making purposes”. It refers to a larger phenomenon than big data or the ‘social data revolution’ — defined as the shift in human communication patterns towards greater personal information sharing, and the implications of this. |
| Data scientist or data science | a professional or a field that focuses on solving real-world problems using large amounts of data by combining skills from often distinct areas of expertise: maths, computer science (for example, hacking and coding), statistics, social science and even storytelling or art. |
| (New) Digital divide | the differential access and ability to use information and communications technologies between individuals, communities and countries — and the resulting socioeconomic and political inequalities. The skills and tools required to absorb and analyse the growing amounts of data produced by such technologies may lead to a ‘new digital divide’. |
| False positives versus false negatives (or type I versus type II errors) | a false positive or type I error refers to a prediction or conclusion that turns out to be false — for example, a fire alarm going off when there is no fire, or an experiment indicating a medical treatment has worked when it had not. A false negative or type II error refers to cases when a study or a monitoring system fails to identify an event or effect that has occurred. Attempts to predict rare events, such as political revolutions, using increasingly rich data and powerful tools are expected to lead to more false positive than false negative results (also known as over-prediction). |
| Internal versus external validity | internal validity refers to the extent to which a causal relationship can be confidently established between two phenomena — a reduction in speed limit and a fall in road deaths, for example. This requires all other factors that may affect the outcome and offer alternative explanations to be taken into account; in this case, this would include a change in drinking habits. External validity refers to the extent to which a study’s conclusions can be confidently generalised to other situations and people. In other words, whether they would hold beyond the area and time for which they were established. |
| Statistical machine learning | a subset of data science, falling at the intersection of traditional statistics and machine learning. Machine learning refers to the construction and study of computer algorithms — step-by-step procedures used for calculations and classification — that can ‘learn’ when exposed to new data. This enables better predictions and decisions to be made based on what was experienced in the past, as with filtering spam emails, for example. The addition of “statistical” reflects the emphasis on statistical analysis and methodology, which is the main approach to modern machine learning. |
This article is part of the Spotlight on Data for development.
References
[1] Andreas Weigend
[2] The new data refineries: transforming big data into decisions. (Technology Services Industry Association blog, covering a talk by Andreas Weigend. 6 January 2014)
[3] Shanta Devarajan. Africa’s statistical tragedy. (World Bank blog, 6 October 2011)
[4] Marcelo Giugale. Fix Africa’s statistics. (The World Post 18 December 2012)
[5] Joseph Hellerstein. The commoditization of massive data analysis. (Blog on O’Reilly.com 19 November 2008)
[6] Data data everywhere. Kenneth Cukier interviewed for The Economist (25 February 2010)
[7] Emmanuel Letouzé. Big data for development: opportunities and challenges. (UN Global Pulse, May 2012)
[8] Big data, big impact: new possibilities for international development. (World Economic Forum, 2012)
[9]James Manyika and others. Big data: the next frontier for innovation, competition and productivity. (McKinsey Global Institute May 2011)
[10] Danah Boyd and Kate Crawford. Six provocations for Big Data. (A Decade in Internet Time: Symposium on the Dynamics of the Internet and Society, September 2011)
[11] The physical size of big data. Infographic by Domo. (14 May 2013)
[12] Christopher Frank. Improving decision making in the world of Big Data. (Forbes, 25 March 2012)
[13] Reinventing society in the wake of Big Data. A Conversation with Alex (Sandy) Pentland (Edge, 30 August 2012)
[14] Eric Bouillet, and others. Processing 6 billion CDRs/day: from research to production (experience report) pp. 264-67 in Proceedings of the 6th ACM International Conference on Distributed Event-Based Systems (2012)
[15] Social impact through satellite remote sensing: visualising acute and chronic crises beyond the visible spectrum. (UN Global Pulse, 28 November 2011)
[16] Michael Horrigan. Big Data: a perspective from the BLS. Column written for AMSTATNEWS, the magazine of the American Statistical Association. (1 January 2013)
[17] Gary King. Big Data is not about the data! Presentation (Harvard University USA, 19 November 2013)
[18] Sanjeev Sardana Big Data: it's not a buzzword, it’s a movement (Forbes blog, 20 November 2013)
[19] Melamed C. Development data: how accurate are the figures? (The Guardian, 31 January 2014)
[20] 2010 World population and housing census programme. United Nations Statistics Division.
[21] Laura Gray. How to boost GDP stats by 60% (BBC News Magazine, 9 December 2012)
[22] Nigeria's economy will soon overtake South Africa's (The Economist, 21 January 2014)
[23] The billion prices project. Massachusetts Institute of Technology
[24] Measuring economic sentiment (The Economist, 18 July 2012)
[25] Piet Daas and Mark van der Loo, Big Data (and official statistics) Working paper prepared for the Meeting on the Management of Statistical Information Systems. (23-25 April 2013)
[26] Rebecca Tave Gluskin and others. Evaluation of Internet-Based Dengue Query Data: Google Dengue Trends. (PLOS Neglected Tropical Diseases, 27 February 2014)
[27] Emilio Zagheni and others. Inferring international and internal migration patterns from Twitter data. (World Wide Web Conference, April 7-11, 2014, Seoul, Korea)
[28] New primer on mobile phone network data for development. (UN Global Pulse, 5 November 2013)
[29] Joshua Blumenstock and others. Motives for mobile phone-based giving: evidence in the aftermath of natural disasters (30 December, 2013)
[30] Michael Wu. Big Data Reduction 3: from descriptive to prescriptive. (Science of Social blog, Lithium 10 April 2013)
[31] Arvind Narayanan and Vitaly Shmatikov Robust de-anonymization of large sparse datasets. Pages 111-125 in Proceedings of the 2008 IEEE Symposium on Security and Privacy (IEEE Computer Society Washington, DC, USA 2008)
[32] Yves-Alexandre de Montjoye and others. Unique in the Crowd: The privacy bounds of human mobility (Nature scientific reports 25 March 2013)
[33] Erica Goode. Sending the police before there’s a crime. (The New York Times, 15 August 2011)
[34] It is getting easier to foresee wrongdoing and spot likely wrongdoers (The Economist, 18 July 2013)
[35] Kate Crawford. Think again: Big Data. Why the rise of machines isn’t all it’s cracked up to be. (Foreign Policy, 9 May 2013)
[36] Neil M. Richards and Jonathan H. King. Three paradoxes of Big Data. (Stanford Law Review, 3 September 2013)
[37] Neil M. Richards and Jonathan H. King. Big Data ethics. (Wake Forest Law Review, 23 January 2014)
[38] Neil M. Richards and Jonathan H. King. Gigabytes gone wild. (Aljazeera America, 2 March 2014)
[39] Rahul Bhargava. Toward a concept of popular data. (MIT Center for Civic Media, 18 November 2013)
[40] James Manyika and others. Open data: unlocking innovation and performance with liquid information (McKinsey Global Institute, October 2013)
[41] Emmanuel Letouzé. The Big Data revolution should be about knowledge security (Post-2015.org, 1 April 2014)
More on Data