Por: Emmanuel Letouzé
Enviar a un amigo
Los detalles proporcionados en esta página no serán usados para enviar correo electrónico no solicitado y no se venderán a terceros. Ver política de privacidad.
¿Qué es Big data? ¿Transformará la política de desarrollo? Emmanuel Letouzé examina en detalle este nuevo campo.
En solo unos pocos años el Big data ha afectado a industrias y algunas actividades, desde el mercadeo y la publicidad hasta la recolección de información de inteligencia y cumplimiento de la ley, suscitando entusiasmo y escepticismo al mismo tiempo. Todo parece indicar que la formulación de políticas se convertirá cada vez más en la próxima frontera del Big data. De ser así, este fenómeno —que el experto Andres Weigend llama el ‘nuevo petróleo’ que necesita ser refinado— ¿será una bendición o una maldición para el desarrollo humano y el progreso social? [1, 2]
Para los optimistas es una revolución que va a cambiar, básicamente para mejorar “cómo vivimos, pensamos y trabajamos” (al respecto vea el video en inglés de Kenneth Cukier de The Economist). Algunos funcionarios del Banco Mundial incluso han expresado la esperanza de que la “tragedia estadística de África” —es decir, la escasez de estadísticas oficiales confiables en algunos de los lugares más pobres del mundo— sea reparada por el Big data. [3, 4] Sin embargo, los escépticos y críticos son más cautelosos, y algunos claramente antagónicos, y se refieren al Big data como un gran engaño, un exagerado despliegue publicitario, un gran riesgo y, por supuesto, al ‘hermano mayor’, a raíz de las revelaciones del ex contratista de la Agencia de Seguridad Nacional, Edward Snowden.
Ganando terreno
Big data, especialmente en relación con los temas de desarrollo y políticas públicas, está en su infancia intelectual y operativa. Joe Hellerstein, científico informático de la Universidad de California, Berkeley, Estados Unidos, hizo una mención anticipada de una inminente “Revolución Industrial de Datos” en noviembre de 2008, mientras que The Economist se refirió a un “diluvio de datos” a comienzos de 2010. [5, 6] Big data se convirtió en un término predominante desde hace solamente un par de años. Las búsquedas de Google (Ver Figura 1) tienen una métrica que lo demuestra: el número de búsquedas que incluyen este término no despegó hasta 2011-2012. En esos dos años, se publicaron cuatro importantes informes: de Pulso Global de la ONU, del Foro Económico Mundial, del Instituto Global McKinsey y de Danah Boyd y Kate Crawford, investigadoras de Microsoft e instituciones académicas. [7-10]
En los últimos tres años, las publicaciones e iniciativas sobre ‘Big data para el desarrollo’ o ‘ciencia de datos para bienes sociales’ se han convertido en una fuente de Big data en sí mismas.
Por supuesto, el rumor sobre Big data puede ser solamente una burbuja, o simplemente una exageración: como lo señalan algunos observadores, el análisis automatizado de grandes conjuntos de datos no es nuevo. Entonces ¿de qué se trata?
¿Qué es big data?
No existe una definición consensuada sobre lo que significa Big Data. Para unos, son los datos generados a través de nuestro uso creciente de dispositivos y herramientas digitales, y plataformas compatibles con la web en nuestra vida diaria. En un minuto, cientos de millones de individuos alrededor del mundo usan alguno de los siete u ocho mil millones de teléfonos celulares para hacer una llamada, enviar un mensaje de texto o un correo electrónico. O pueden enviar dinero, comprar un libro, hacer una búsqueda en línea, pagar una comida con su tarjeta de crédito, actualizar su estado en Facebook, enviar tweets, subir videos a YouTube, publicar una entrada en su blog, etcétera. Cada una de estas acciones deja una huella digital. La suma de esta información digital constituye el grueso del Big data. Cada año, a partir de 2012, se producen más de 1,2 zetabytes, o sea 1021 bytes, suficientes para llenar 80 mil millones de iPhones de 16GB (que darían más de cien vueltas al planeta). (Tabla 1). Y el volumen de estos datos está creciendo rápidamente. [11] Por lo tanto, volumen, velocidad y variedad son las tres ‘V’ que caracterizan al Big data, añadiéndose a menudo una cuarta V, correspondiente al valor que podría extraerse de esos datos.
Tabla 1— ‘Inflación’ de datos
| Unidad | Tamaño | Significado |
|---|---|---|
| Bit (b) | 1 o 0 | Abreviatura de “dígito binario”, usado por las computadoras después del código binario (1 o 0) para almacenar y procesar datos, incluyendo textos, números, imágenes, videos, etc. |
| Byte (B) | 8 bits | Información suficiente para crear un número o una letra en inglés en código informático. Es la unidad básica de la informática. |
| Kilobyte (KB) | 1.000 o 210 bytes | Proviene de “mil” en griego. Una página de texto es de 2KB. |
| Megabyte (MB) | 1.000KB o 220 bytes | Proviene de “grande” en griego. Un archivo típico de una canción en formato MP3 es de aproximadamente 4MB. |
| Gigabytes (GB) | 1.000MB o 230 bytes | Proviene de “gigante” en griego. Una película de dos horas de duración se puede comprimir en 1-2GB. Un archivo de texto de 1GB contiene mil millones de caracteres, o aproximadamente 290 copias de las obras completas de Shakespeare. |
| Terabyte (TB) | 1.000GB o 240 bytes | Proviene de “monstruo” en griego. Todos los libros catalogados en la Biblioteca del Congreso de los Estados Unidos equivalen a 15TB. Todos los tweets enviados antes de finalizar el 2013 llenarían aproximadamente 18.5TB de archivos de texto. La impresión de ese archivo (a un ritmo de 15 páginas, tamaño A4 por minuto) demoraría más de 1200 años. |
| Petabyte (PB) | 1.000TB o 250 bytes | La NSA supuestamente analiza el 1,6 por ciento del tráfico mundial de Internet, o aproximadamente 30PB por día. Tocar ininterrumpidamente 30PB de música demoraría más de 60.000 años, que corresponde al tiempo transcurrido desde que el primer Homo sapiens salió de África. |
| Exabyte (EB) | 1.000PB o 260 bytes | 1EB de datos corresponde a una capacidad de almacenamiento de 33.554.432 dispositivos de iPhone5 con una memoria de 32GB. Se prevé que para 2018, el volumen total del tráfico mensual de datos móviles será aproximadamente la mitad de un EB. Si este volumen de información fuera almacenado en dispositivos iPhone5 de 32GB apilados uno encima de otro, su tamaño sería 283 veces la altura del Empire State Building. |
| Zettabyte (ZB) | 1.000EB o 270 bytes | Se estima que en 2013 la humanidad generó 4 a 5ZB de datos, que excedieron en 46 billones la cantidad de información de las ediciones impresas de The Economist. Si esa cantidad de revistas fuera puesta hoja por hoja en el suelo, cubriría la superficie total de la Tierra. |
| Yottabyte (YB) | 1.000ZB o 280 bytes | El contenido del código genético humano puede ser almacenado en menos de 1,5GB, lo que implica que 1YB de almacenamiento contendría el genoma de más 800 billones de personas, o de aproximadamente 100.000 veces la población total del mundo. |
Si la población, debido a un repentino estallido de fertilidad, se hiciera más grande y joven, la proporción de la información digital producida recientemente seguiría creciendo cada vez más rápido: más del 90 por ciento de los datos mundiales fueron creados hace tan solo dos años (2010-2012), según un informe muy mencionado. [12]
Tipo de datos
Hay diferentes tipos de Big data. El primero se refiere a pequeños pedazos de datos ‘duros’ —números o hechos, por ejemplo— descritos por Alex ‘Sandy’ Pentland, profesor del Instituto Tecnológico de Massachusetts, de los Estados Unidos, como “migajas digitales”. [13] Se dice que son ‘estructurados’ porque constituyen conjuntos de datos de variables que pueden ser fácilmente etiquetados, categorizados y organizados (en columnas y filas por ejemplo) para un análisis sistemático. Otro ejemplo son los Registros de Detalles de Llamadas (CDR por sus siglas en inglés) recogidos por los operadores de teléfonos móviles (Tabla 2). Los CDR son metadatos (datos sobre datos) que capturan el uso que los suscriptores dan a sus celulares —incluyendo un código de identificación y, como mínimo, la ubicación de la torre de telefonía que direcciona la llamada de quien llama y de quien la recibe— y el tiempo y duración de la llamada. Los grandes operadores recogen más de seis mil millones de CDR por día. [14] (Figura 2).
Tabla 2. Datos contenidos en un CDR
| Variable | Datos |
|---|---|
| ID de quien llama | X76VG588RLPQ |
| Ubicación ID de la torre del que llama | 2°24' 22.14" , 35°49' 56.54 |
| Número telefónico del destinatario | A81UTC93KK52A81UTC93KK52 |
| Ubicación de la torre celular del destinatario | 3°26' 30.47", 31°12' 18:01" |
| Hora de la llamada | 3013-11-07T15:15:00 |
| Duración de la llamada | 01:12:02 |
Un segundo tipo de Big data está constituido por videos, documentos, publicaciones en blogs y otros contenidos de las redes sociales. La mayor parte de esos datos están ‘desestructurados’ y, por lo tanto, son más difíciles de analizar. Se diferencian de las ‘migajas’ por estar sujetos a las opciones editoriales de sus autores y, al ser subjetivos, pueden brindar un panorama engañoso. Por ejemplo, desde un blog se podría boicotear determinado producto, pero el estado de la tarjeta de crédito del autor puede revelar una preferencia diferente en función de sus compras reales.
Un tercer tipo de Big data se recoge de manera remota mediante sensores digitales y refleja las acciones humanas. Estos podrían ser ‘contadores inteligentes’ instalados en los hogares para registrar el consumo de electricidad, o imágenes satelitales que pueden recoger información física sobre la cubierta vegetal como un indicador de la deforestación. [15]
Hay quienes consideran que el universo del Big data es mucho más amplio —incluyendo registros administrativos, precios o datos climáticos, por ejemplo, o los libros que ya se han digitalizado— lo que, tomado colectivamente, podría constituir un cuarto tipo.
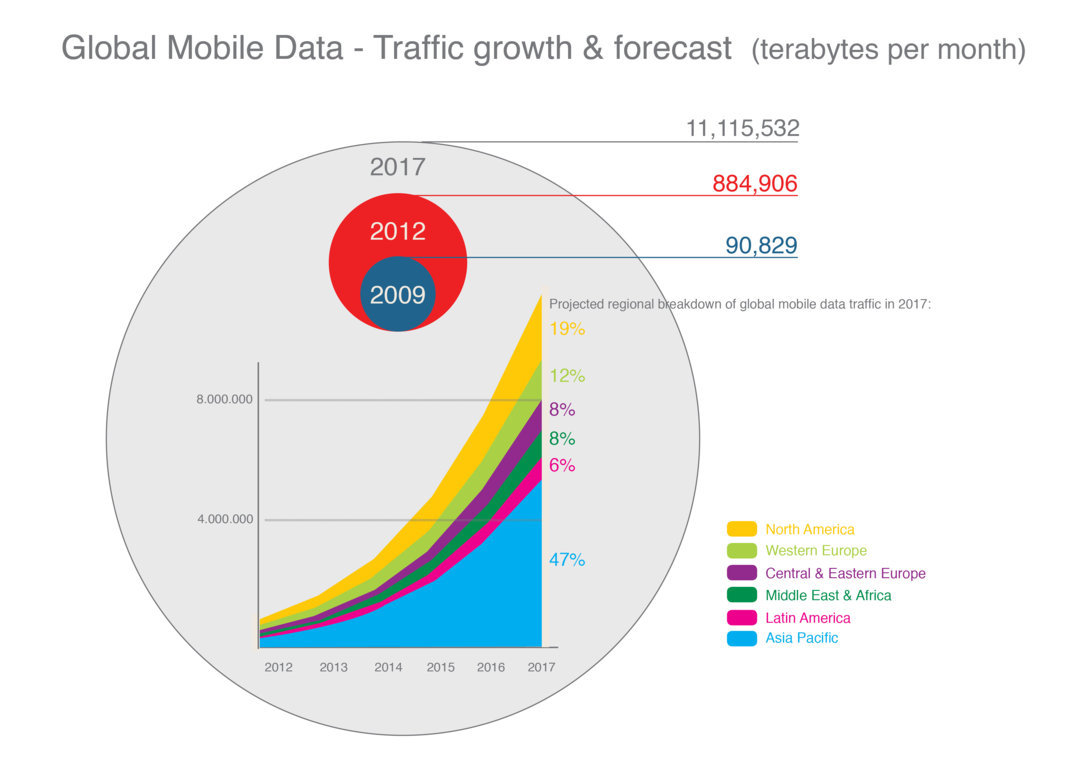
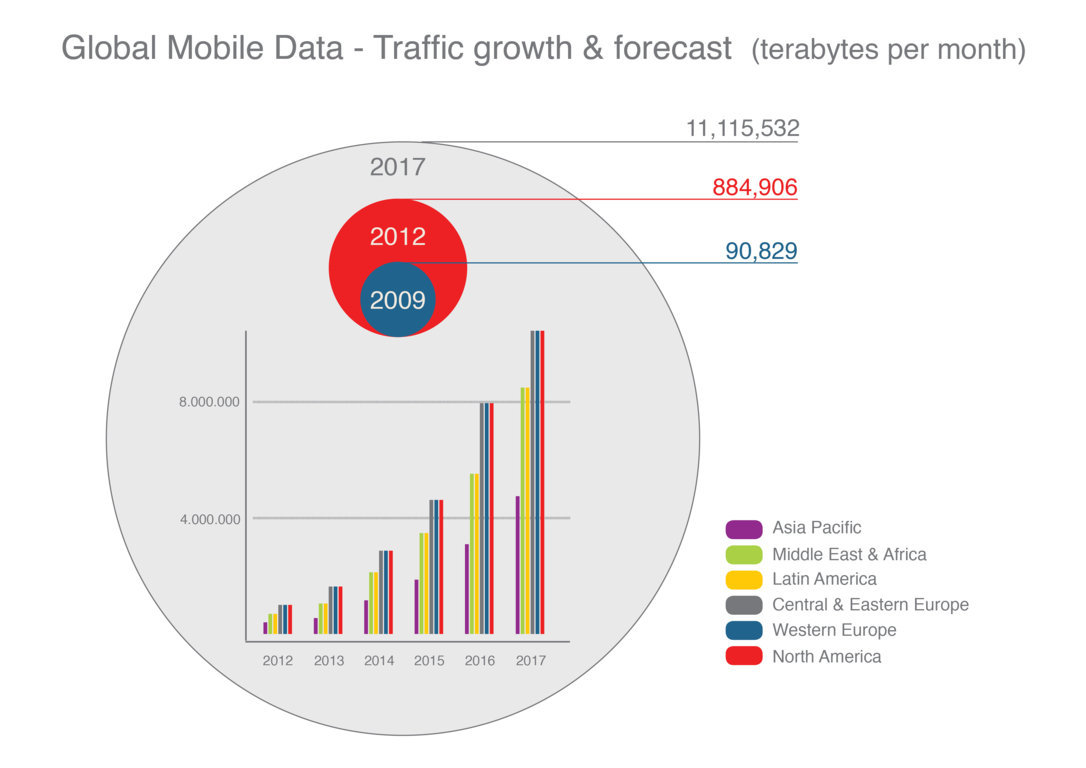 Presione aquí para agrandar la image
Presione aquí para agrandar la image Definición de funciones
Pero el volumen del Big data es de lectura mecánica, generado acerca y por las personas —en alguna combinación de los tipos mencionados anteriormente. Esta información no estaba disponible hace diez años, antes de la era de Facebook o de la explosión en el uso de los celulares— y son resultado de los poderosos cambios tecnológicos y sociales.
La principal novedad del Big data es que proviene de fuentes electrónicas y termina en bases de datos cuyo propósito primordial no es la inferencia estadística. [16] Dicho de otro modo: no se recogen o se sacan muestras con la intención explícita de extraer conclusiones. Esto también hace que usar Big data sea un reto.
Por lo tanto, el término Big data puede ser un nombre poco apropiado y engañoso: el tamaño no es una característica que lo defina. Por ejemplo, una hoja de cálculo de Excel con los CDR podría no ser un archivo de gran tamaño; la base de datos completa de los Indicadores de Desarrollo del Banco Mundial es un gran archivo, pero es el resultado de procesos plenamente controlados, que incluyen encuestas y atribuciones estadísticas llevadas a cabo por organismos oficiales. La diferencia es principalmente cualitativa: está en el tipo de información contenida en los datos y en la manera como ellos se generan.
Para añadir una capa adicional de complejidad: “Big data no tiene que ver con los datos”, como precisa Gary King, profesor de la Universidad de Harvard. [17] Se trata del análisis de grandes volúmenes de datos, lo que en términos generales se refiere a las mejoras en la potencia informática y las capacidades analíticas, tales como máquinas de aprendizaje de estadísticas y algoritmos capaces de buscar y descubrir patrones y tendencias en ingentes cantidades de información compleja. Esta es la segunda característica del Big data: las herramientas y métodos, y la disponibilidad ahora de hardware y software requerido para analizar los datos digitales.
Y una tercera propiedad importante pero menos debatida del Big data es que se ha convertido en un ‘movimiento’ [18] que está atrayendo cada vez más a grupos multidisciplinarios de científicos sociales e informáticos con una “mentalidad de darle sentido a la confusión”; como lo señala Andreas Weigend, científico de datos —en esencia, la definición del Big data como un movimiento para convertir la información en toma de decisiones. [2] Declaraciones como esta han renovado el interés sobre las perspectivas y la promesa de formular políticas ‘basadas en datos’ o ‘basadas en evidencias’— aunque hay implicancias técnicas, tecnológicas, comerciales y políticas que están lejos de ser triviales.
Exactamente ¿de qué manera el Big data — es decir los nuevos tipos de datos, las nuevas capacidades para analizarlos, con nuevas intenciones— puede afectar a las sociedades? ¿Y cómo explicar el alboroto que ha creado?
La promesa se deriva de dos aspectos: suministro de mayor cantidad de datos cada vez, y demanda de mejor información, de forma más rápida y más barata; en otras palabras, hay un tira y afloja por el Big data.
Demanda de datos
La gente está frustrada con las herramientas y sistemas actualmente disponibles para la toma de decisiones. Por ejemplo, un buen indicador de la pobreza o del subdesarrollo de una región es la falta de datos sobre la pobreza o el desarrollo. [19]
Algunos países (la mayoría de ellos con una historia reciente de conflictos) no han tenido un censo en los últimos cuarenta años o más. El tamaño de su población, su estructura y distribución es básicamente una incógnita. Incluso si existen cifras oficiales, generalmente están basadas en datos incompletos. [20] La escasez de datos también implica que las cifras oficiales del PIB de algunos países reciban un impulso de la noche a la mañana —del 40 por ciento en Ghana en 2010, o de 60 por ciento en Nigeria en 2014— cuando los cambios en la estructura de sus economías, como el crecimiento del sector tecnológico, finalmente son tomados en cuenta. [21, 22]
Esta falta de datos confiables ha presidido el reciente llamado de la ONU para una ‘revolución de los datos’. La razón básica es que, en la era del Big data, las economías deben ser dirigidas por formuladores de políticas que dependan de mejores instrumentos de navegación e indicadores que les permitan diseñar y llevar a la práctica políticas y programas más ágiles y mejor direccionados. Se dice que el Big data tiene potencial para que los sistemas estadísticos nacionales en áreas con escasez de datos ‘den el salto’ al futuro, del mismo modo que muchos países pobres pasaron de la etapa de los teléfonos fijos a la de los teléfonos celulares. [4]
Suministro de nuevo conocimiento
El atractivo del potencial salto hacia delante también incluye el ‘lado del suministro’ del Big data. Existe una evidencia preliminar práctica y un creciente cúmulo de trabajo acerca del novedoso potencial del Big data para comprender y afectar las poblaciones y los procesos humanos.
Por ejemplo, el Big data ha sido usado para realizar en línea seguimientos de la inflación, estimar y predecir los cambios en el PIB en tiempo casi real, controlar el tráfico e incluso el brote del dengue. [23-26] Los datos del monitoreo de las redes sociales para analizar los sentimientos de la gente está abriendo nuevas vías para la medición del bienestar, mientras que la información de los correos electrónicos y de Twitter podría usarse para estudiar la migración interna e internacional. [25-27] Y una literatura académica especialmente rica y en crecimiento está usando los CDR para estudiar los patrones de migración, los niveles socioeconómicos y la expansión de la malaria, entre otros.
La guía para analizar el Big data, publicada por Pulso Global de la ONU, pone énfasis en cuatro aspectos: respuesta a desastres, salud pública, pobreza y niveles socioeconómicos, y movilización y transporte humano. (Ver Recuadro 1). [28]
Recuadro 1: Ejemplos de análisis de información de teléfonos celulares, basados en la cartilla de Pulso Global de la ONU y el Informe de Datos sobre Desastres Mundiales 2013. |
|
Se usó la información de las transferencias de dinero tras el terremoto de 2008 en Ruanda para analizar el momento, la magnitud y la motivación de las donaciones a las comunidades afectadas, lo que reveló en particular que las donaciones tuvieron más probabilidad de beneficiar a las personas más ricas. [29] El análisis de los CDR se ha usado para estudiar la propagación de las enfermedades infecciosas y su control en una barriada urbana de Kibera, Kenia. Una vía especialmente prometedora es usar los CDR para predecir los niveles socioeconómicos. Se realiza superponiendo y combinando indicadores basados en los CDR (como el volumen promedio de llamadas en una zona) con variables socioeconómicas conocidas (como los niveles de ingreso) para construir modelos estadísticos capaces de ‘predecir’ patrones y tendencias (Ver Figura 3).
 Presione aquí para agrandar la imagen Presione aquí para agrandar la imagenEn cuanto a movilización y transporte humano, Orange proporcionó los CDR de Costa de Marfil en el marco del desafío D4D (Datos para el Desarrollo), ayudando a hacer modelamientos de las rutas de autobuses en Abijan y mostrando que el tiempo de viaje se podía reducir en un diez por ciento. Este tipo de análisis utiliza: Información del tráfico en tiempo real. Por ejemplo, las alertas de tráfico de Google proporcionan a los consumidores información de sus viajes diarios utilizando una combinación de fuentes de información, algunas públicas (como los programas de construcción), algunas privadas (como las empresas de telecomunicaciones que rastrean los dispositivos individuales de los usuarios para calcular el tiempo al trabajo) y algunas generadas de manera pasiva (por ejemplo, un grupo de llamadas realizadas desde una ubicación similar podría indicar un embotellamiento de tráfico). Mejor comprensión de los hábitos de transporte. Esto requiere sincronizar los datos de viaje que se derivan de los celulares con otros datos socioeconómicos que revelen un patrón de preferencias en los hábitos de transporte (en oposición a las preferencias declaradas, que se derivan de las encuestas). Un ejemplo está en el Reino Unido, donde los trenes de la costa este usaron datos de Telefónica para entender mejor los hábitos de los pasajeros de la ruta Londres – Edimburgo.
Fuentes: |
Mientras tanto, varios otros autores han propuesto de qué manera el Big data podría beneficiar al desarrollo. Pulso Global de la ONU distinguió los usos de la ‘alerta temprana’ del ‘conocimiento en tiempo real’, o del ‘monitoreo en tiempo real’ del impacto de una política. Otros comparan su función descriptiva (como un mapa en tiempo real) con las funciones predictivas y de diagnóstico. (Ver Tabla 3). [7, 30]
Tabla 3 Uso real y potencial del Big data para el desarrollo
|
Aplicación
|
Explicación | Ejemplos | Comentario y advertencia |
|---|---|---|---|
CLASIFICACIÓN PULSO GLOBAL DE ONU |
|||
| 1. Descriptiva | Big data puede documentar y transmitir lo que está pasando. | Esta aplicación es muy similar a la aplicación 'conocimiento en tiempo real', aunque es menos ambiciosa en sus objetivos. Cualquier infografía, incluyendo los mapas, que hace legibles a los lectores vastas cantidades de datos es un ejemplo de aplicación descriptiva. | La descripción de datos siempre implica hacer elecciones y suposiciones – acerca de qué datos se van a mostrar y de qué manera- que requieresn ser explícitas y comprensibles; es bien sabido que incluso los gráficos de barras y los mapas pueden ser engañosos. |
| 2. Predictiva | Big data puede dar una idea de lo que probablemente vaya a pasar independientemente del por qué. | Un tipo de ‘predicción’ se refiere a lo va a pasar después, el patrullaje predictivo mencionado más adelante es un ejemplo. Otro tipo se refiere a predecir -a través de Big data– las condiciones imperantes, como en los casos de los niveles socioeconómicos que usan los CDR en América Latina y Costa de Marfil. | Se aplican los mismos comentarios de las aplicaciones de 'alerta temprana' y 'conocimiento en tiempo real'. |
| 3. Prescriptiva o de diagnóstico | Big data podría arrojar luz sobre el por qué suceden las cosas y lo que se podría hacer al respecto. | Hasta ahora no hay ejemplos claros de esta aplicación en contextos de desarrollo. el ejemplo de los datos de los CDR usados para mostrar que las rutas de los autobuses en Abijan podrían 'optimizarse' es más cercano a un caso donde el análisis permite identificar los vínculos causales y se pueden diseñar políticas. | Son válidos la mayoría de comentarios de la aplicación ‘retroalimentación en tiempo real’. En sentido estricto, un ejemplo de la aplicación de diagnóstico requeriría ser capaz de asignar causalidad. La aplicación prescriptiva trabaja mejor, en teoría, cuando es apoyada por sistemas de retroalimentación y circuitos sobre el efecto de las acciones políticas. |
CLASIFICACIÓN ALTERNATIVA |
|||
| 1. Alerta temprana | Detección temprana de anomalías en el uso por parte de la población de dispositivos y servicios digitales que pueden permitir una respuesta más rápida en tiempos de crisis. | Patrullaje predictivo, basado en la noción de que el análisis de los datos históricos puede revelar ciertas combinaciones de factores asociados con una mayor probabilidad de aumento de la criminalidad en un área determinada; también se puede usar para asignar recursos policiales. Las Tendencias de la Gripe de Google es otro ejemplo, donde se analizan las búsquedas de términos particulares (“flujo nasal”, “picazón de ojos”) para detectar el inicio de la temporada de gripe, aunque su precisión es objeto de debate. | Esta aplicación asume que se pueden observar y modelar ciertas regularidades del comportamiento humano. Los principales desafíos políticos incluyen la tendencia de mal funcionamiento de la mayoría de los sistemas de detección, y de exceso de predicción de parte de los modelos de pronósticos, es decir tienen una mayor prevalencia de dar ‘falsos positivos’. |
| 2. Conocimiento en tiempo real | Big data puede hacer una representación detallada y actualizada de la realidad, lo cual permite informar al diseño y orientación de programas y políticas. | Usando datos publicados por Orange, los investigadores encontraron un alto grado de asociación entre las redes sociales y la distribución de idiomas en Costa de Marfil, lo que sugiere que dichos datos podrían proporcionar información sobre las comunidades lingüísticas en los países donde no está disponible. | El atractivo y el argumento subyacente de esta aplicación es la noción de que el Big data puede ser un sustituto de los datos malos o escasos; sin embargo, los modelos que muestran altas correlaciones entre los indicadores ‘basados en Big data’ y los ‘tradicionales’ generalmente requieren de la disponibilidad de estos últimos para ser entrenados y construidos. ‘Tiempo real’ significa aquí el uso de datos digitales de alta frecuencia para obtener un panorama de la realidad en un momento determinado. |
| 3. Retroalimentación en tiempo real | La habilidad de monitorear una población en tiempo real hace posible entender dónde están fallando las políticas y programas, y hacer los ajustes que se requieren. | Las corporaciones privadas ya están usando los análisis de Big data. Para el desarrollo, esto podría incluir analizar el impacto de una acción política —por ejemplo la introducción de nuevas regulaciones de tráfico— en tiempo real. |
Aunque atractiva, existen pocos ejemplos reales (si los hay) de esta aplicación; un reto es garantizar que cualquier cambio observado pueda atribuirse a la intervención o ‘tratamiento’. Sin embargo, los datos de alta frecuencia también pueden contener ‘experimentos naturales’ —como una caída repentina en los precios en línea de un bien determinado—que pueden aprovecharse para inferir causalidad. |
Riesgos y desafíos
Obviamente, la promesa del Big data ha sido recibida con advertencias sobre sus peligros. Los riesgos, desafíos y, de manera más general, las preguntas difíciles se articularon ‘anticipadamente’ desde 2011. [10]
Quizás los riesgos más graves —y las vías más urgentes para la investigación y el debate—sean los derechos individuales, la privacidad, la identidad y la seguridad. Además de la obvia intrusión en actividades de vigilancia y cuestiones en torno a su legalidad y legitimidad, hay importantes preguntas sobre el anonimato de los datos: lo que significa y sus límites. Un estudio sobre el alquiler de películas mostró que incluso los datos anónimos pueden dejar de serlos, vinculándolos a un individuo conocido tan solo correlacionando las fechas de alquiler de unas tres películas con las fechas de publicaciones en alguna plataforma en línea de películas. [31] Otra investigación encontró que los CDR que registran la ubicación y el tiempo se pueden volver a individualizar incluso cuando están exentos de cualquier identificador individual. En ese caso, teóricamente son suficientes cuatro puntos de datos para escoger a los individuos dentro de un conjunto completo de datos con un 95 por ciento de exactitud. [32]
Los críticos también señalan los riesgos asociados a tomar decisiones basadas en datos sesgados o análisis dudosos (a veces llamados amenazas a la validez externa e interna). Si los formuladores de políticas llegan a creer que ‘los datos no mienten’, tales riesgos podrían ser especialmente preocupantes. En el Recuadro 2 se dan algunos ejemplos.
Recuadro 2. Big data – los riesgos de sacar conclusiones válidas |
|
Un desafío fundamental del Big data es que las personas que los producen se han seleccionado a sí mismas como generadores de datos de su actividad. En términos técnicos esto es un ‘sesgo de selección’ y significa que el análisis del Big data probablemente producirá un resultado distinto al de una encuesta (o sondeo) tradicional, que busca una muestra representativa de la población. Por ejemplo, tratar de responder a la pregunta: “los habitantes del país A ¿prefieren arroz o papas fritas?” mediante la minería de datos de Twitter estaría sesgada en favor de las preferencias de la gente joven porque son los mayores usuarios de esta red. Por lo tanto, los análisis basados en el Big data podrían carecer de ‘validez externa’, aunque es posible que los individuos que difieren en casi todos los aspectos puedan tener preferencias similares y mostrar comportamientos idénticos (los jóvenes pueden tener las mismas preferencias que la gente mayor). Otro riesgo proviene de los análisis que son deficientes porque carecen de ‘validez interna’. Por ejemplo, una fuerte caída en el volumen de los CDR de un área podría interpretarse, basándose en hechos del pasado, como anuncio de que se avecina un conflicto. Pero en realidad podría ser causado por algo diferente, como una baja en la torre de telefonía móvil del área. |
Otro riesgo es que el análisis basado en el Big data se enfoque demasiado en la correlación y predicción, a expensas de las causas, el diagnóstico o la inferencia, sin lo cual la política sería esencialmente ciega. Un buen ejemplo es el ‘patrullaje predictivo’. Aproximadamente desde 2010, la policía y las fuerzas del orden público en algunas ciudades de Estados Unidos y del Reino Unido han procesado datos para evaluar la probabilidad del aumento de la delincuencia en ciertas áreas, prediciendo un aumento basándose en patrones históricos.
Las fuerzas despachan sus recursos en consonancia con los resultados, lo que ha reducido el crimen en la mayoría de casos. [3] No obstante, a menos que se conozca por qué está aumentando la delincuencia, no es posible poner en marcha políticas de prevención que aborden las causas fundamentales o los factores que contribuyen a ello. [34]
Sin embargo, otro gran riesgo no ha recibido la atención que se merece: es el potencial del Big data de crear una ‘nueva división digital’ que podría ampliar en vez de cerrar las brechas existentes en los ingresos y el poder en todo el mundo. [35] Una de las ‘tres paradojas’ del Big data es que debido a que requiere capacidades analíticas y acceso a información que solo posee una fracción de instituciones, corporaciones e individuos, la revolución de los datos podría debilitar a las propias comunidades y países a los que promete servir. [36] Las personas con mayor cantidad de datos y capacidades estarían en mejor posición de explotar el Big data para lograr ventajas económicas, aunque digan que la usan para beneficiar a otros.
Un desafío básico y relacionado es usar los datos efectivamente. Todas las discusiones acerca de la ‘revolución de datos’ asumen que ‘el problema de los datos’, esa escasez de datos, es parcialmente la culpable de las malas políticas. Pero la historia ha mostrado que la falta de datos o de información ha jugado históricamente un papel marginal en las decisiones que conducen a malas políticas o escasos resultados. Y un ‘algoritmo’ ciego puede socavar en el futuro los propios procesos que pretenden garantizar que los datos se conviertan en decisiones que estén sujetas a la supervisión democrática.
Un gran futuro
Pero así como es muy poco probable que disminuya el crecimiento de la producción de datos, del mismo modo es poco probable que la ‘burbuja del Big data’ estalle en un futuro cercano. El mundo puede esperar más artículos y controversias sobre el potencial y los peligros del Big data para el desarrollo. Su futuro probablemente estará configurado por tres líneas principales: la investigación académica, los marcos legales y técnicos para el uso ético de los datos, y una mayor demanda de la sociedad para una mejor rendición de cuentas.
La investigación continuará examinando si y cómo se pueden empujar las fronteras metodológicas y científicas, especialmente en dos áreas: extraer inferencias más sólidas y medir y corregir los sesgos en las muestras.
El debate político desarrollará marcos y estándares —normativos, legales y técnicos—para recoger, almacenar y compartir Big data. Esos desarrollos se incluyen bajo el término ‘ética de Big data’. [37, 38] Los avances técnicos ayudarán, por ejemplo, inyectando ‘ruido’ en los conjuntos de datos para hacer más difícil la re-identificación de los individuos en ellos representados. No obstante, un enfoque exhaustivo de la ética del Big data idealmente abarcará otras consideraciones humanísticas como la privacidad y la igualdad, y la defensa de la alfabetización de datos. [39]
Una tercera influencia sobre el futuro del Big data será cómo se compromete y evoluciona con el movimiento de datos ‘abiertos’ y sus impulsores sociales subyacentes, donde los ‘datos abiertos’ se refieren a información fácilmente accesible en forma gratuita o a un costo insignificante, de lectura mecánica y con mínimas limitaciones de uso, transformación y distribución. (Ver Figura 4) [40]

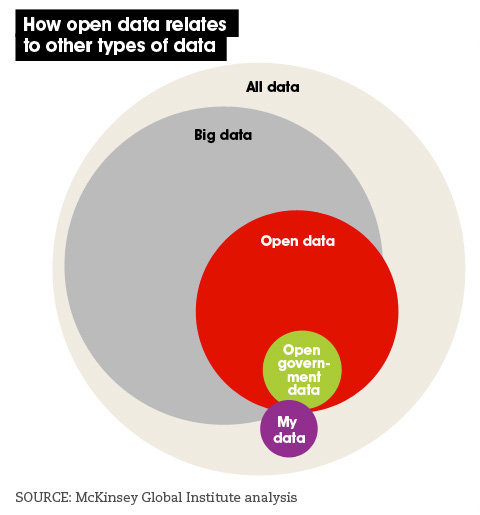 Presione aquí para agrandar la imagen
Presione aquí para agrandar la imagenEn el futuro inmediato, el Big data y los movimientos de datos abiertos constituirán dos pilares principales de una ‘revolución de datos’ más grande. Ambos nacen en un contexto de una creciente demanda pública para una mayor apertura, agilidad, transparencia y rendición de cuentas de los datos y acciones públicas. Las connotaciones políticas —tan fácilmente olvidadas— son claras. Y por lo tanto una ‘verdadera’ revolución del Big data debe ser aquella donde los datos se puedan aprovechar para cambiar las estructuras de poder y los procesos de toma de decisiones, y no solamente para crear ideas. [41]
Kaz Janowski habla con Philipp Schönrock, director del Centro de Pensamiento CEPEI con sede en Colombia, sobre lo que se necesita para hacer que el Big data trabaje para el desarrollo. La conversación analiza el significado de la ‘revolución de los datos’ y del desglose de los mismos, el papel de las oficinas tradicionales de estadísticas y del sector privado, la necesidad de regulaciones y de un marco legal, y cómo avanzar en la construcción de confianza en el manejo de datos.
Emmanuel Letouzé es candidato a doctorado por la Universidad de California, Berkeley, miembro de la Iniciativa Humanitaria de Harvard, profesor visitante del Laboratorio de Medios del MIT e investigador asociado del Instituto de Desarrollo de Ultramar. Se le puede escribir a [email protected] y en Twitter @Data4Dev.
La versión original de este artículo se publicó en la edición global de SciDev.Net
| Definiciones | |
|---|---|
| Algoritmos (y futuro algorítmico) | En matemáticas y ciencias informáticas, se denomina algoritmo a una serie de instrucciones predefinidas o reglas escritas en lenguaje de programación diseñadas para ordenarle a la computadora cómo resolver secuencialmente un problema recurrente mediante cálculos y procesamiento de datos. El uso de algoritmos para la toma de decisiones ha aumentado en varios sectores y servicios como el policial y bancario. Esto ha generado esperanzas —y preocupaciones— sobre el advenimiento de un ‘futuro algorítmico’ donde los algoritmos podrían reemplazar las funciones humanas o incluso llegar a ser un instrumento de represión. |
| Big data | Concepto genérico que, en pocas palabras, es sinónimo de una o más de estas tres tendencias: el volumen creciente de datos digitales generados diariamente como subproducto del uso de dispositivos digitales por parte de la gente; las nuevas tecnologías, herramientas y métodos disponibles para analizar grandes conjuntos de datos que no están diseñados para el análisis; y la intención de extraer de esos datos y herramientas ideas para la formulación de políticas. |
| (Nueva) Brecha digital | Acceso diferenciado y capacidad de usar las tecnologías de información y las comunicaciones entre personas, comunidades y países, y las desigualdades socioeconómicas y políticas resultantes. Las habilidades y herramientas requeridas para absorber y analizar las crecientes cantidades de datos producidos por dichas tecnologías podrían conllevar a una ‘nueva brecha digital’. |
| Científico de datos o ciencia de datos | Profesional o campo dirigido a resolver los problemas del mundo real usando grandes cantidades de datos mediante la combinación de competencias aportadas por distintas áreas de especialización: matemáticas, ciencias informáticas (por ejemplo piratería y codificación), estadísticas, ciencias sociales e incluso narraciones o arte. |
| Falsos positivos versus falsos negativos (o errores tipo I versus errores tipo | Un falso positivo, o error de tipo I, se refiere a una predicción o conclusión que resulta ser falsa, por ejemplo, una alarma de incendio cuando no hay incendio, o un experimento que indica que un tratamiento médico ha sido efectivo cuando en realidad no fue así. Un falso negativo, o error de tipo II, se refiere a aquellos casos donde un estudio o un sistema de monitoreo no identifica un evento o un efecto que ha ocurrido. Se espera que los intentos de predecir eventos poco comunes, como las revoluciones políticas, mediante el uso cada vez más creciente de datos abundantes y herramientas poderosas conducirán a dar más falsos positivos que falsos negativos (también conocidos como exceso de predicción). |
| Máquinas de aprendizaje de estadísticas | Subconjunto de datos científicos, que caen en la intersección entre estadísticas tradicionales y máquinas de aprendizaje. Las máquinas de aprendizaje se refieren a la construcción y estudio de algoritmos informáticos —procedimientos paso a paso utilizados para el cálculo y la clasificación— que se pueden ‘aprender’ al exponerse a nuevos datos. Esto permite hacer mejores predicciones y decisiones sobre la base de lo que se experimentó en el pasado, como filtrar correos electrónicos basura, por ejemplo. Al añadírseles la palabra “estadísticas” se quiere mostrar el énfasis en el análisis y la metodología estadística, que es el enfoque principal para las máquinas de aprendizaje modernas. |
| Registro de Detalle de Llamadas (más conocido como CDR por sus siglas en inglés) | Nombre técnico de los datos de los teléfonos celulares registrados por todos los operadores de telecomunicaciones. Los CDR contienen información sobre las ubicaciones de quienes envían y reciben llamadas o mensajes de texto a través de las redes de operadores, y la fecha y tiempo de duración de dichas llamadas. |
| Revolución de datos | Término común en los discursos de desarrollo desde que el Panel de Alto Nivel de Personas Eminentes de la Agenda de Desarrollo posterior a 2015 exhortó a una ‘revolución de los datos’ para “fortalecer la información y las estadísticas en la toma de decisiones y la rendición de cuentas”. Hace referencia a un fenómeno de más envergadura que los grandes volúmenes de datos o la ‘revolución de los datos sociales’, definido como el cambio en los patrones de comunicación humana hacia un mayor intercambio de información personal, y sus implicancias. |
| Validez interna versus validez externa | La validez interna se refiere a la medida en la que se puede establecer con seguridad una relación causal entre dos fenómenos, por ejemplo una reducción en el límite de velocidad con un descenso en las muertes en carreteras. Esto requiere que se tomen en cuenta todos los demás factores que puedan afectar los resultados y ofrecer explicaciones alternativas; en este caso, incluiría un cambio en los hábitos de beber alcohol. La validez externa se refiere a la medida según la cual las conclusiones de un estudio se pueden generalizar con certeza a otras situaciones y personas. En otras palabras, si se mantendrán más allá del lugar y tiempo para el que fueron establecidas. |
Este artículo forma parte del Especial sobre Big data para el desarrollo.
References
[1] Andreas Weigend
[2] The new data refineries: transforming big data into decisions. (Technology Services Industry Association blog, covering a talk by Andreas Weigend. 6 January 2014)
[3] Shanta Devarajan. Africa’s statistical tragedy. (World Bank blog, 6 October 2011)
[4] Marcelo Giugale. Fix Africa’s statistics. (The World Post 18 December 2012)
[5] Joseph Hellerstein. The commoditization of massive data analysis. (Blog on O’Reilly.com 19 November 2008)
[6] Data data everywhere. Kenneth Cukier interviewed for The Economist (25 February 2010)
[7] Emmanuel Letouzé. Big data for development: opportunities and challenges. (UN Global Pulse, May 2012)
[8] Big data, big impact: new possibilities for international development. (World Economic Forum, 2012)
[9]James Manyika and others. Big data: the next frontier for innovation, competition and productivity. (McKinsey Global Institute May 2011)
[10] Danah Boyd and Kate Crawford. Six provocations for Big Data. (A Decade in Internet Time: Symposium on the Dynamics of the Internet and Society, September 2011)
[11] The physical size of big data. Infographic by Domo. (14 May 2013)
[12] Christopher Frank. Improving decision making in the world of Big Data. (Forbes, 25 March 2012)
[13] Reinventing society in the wake of Big Data. A Conversation with Alex (Sandy) Pentland (Edge, 30 August 2012)
[14] Eric Bouillet, and others. Processing 6 billion CDRs/day: from research to production (experience report) pp. 264-67 in Proceedings of the 6th ACM International Conference on Distributed Event-Based Systems (2012)
[15] Social impact through satellite remote sensing: visualising acute and chronic crises beyond the visible spectrum. (UN Global Pulse, 28 November 2011)
[16] Michael Horrigan. Big Data: a perspective from the BLS. Column written for AMSTATNEWS, the magazine of the American Statistical Association. (1 January 2013)
[17] Gary King. Big Data is not about the data! Presentation (Harvard University USA, 19 November 2013)
[18] Sanjeev Sardana Big Data: it's not a buzzword, it’s a movement (Forbes blog, 20 November 2013)
[19] Melamed C. Development data: how accurate are the figures? (The Guardian, 31 January 2014)
[20] 2010 World population and housing census programme. United Nations Statistics Division.
[21] Laura Gray. How to boost GDP stats by 60% (BBC News Magazine, 9 December 2012)
[22] Nigeria's economy will soon overtake South Africa's (The Economist, 21 January 2014)
[23] The billion prices project. Massachusetts Institute of Technology
[24] Measuring economic sentiment (The Economist, 18 July 2012)
[25] Piet Daas and Mark van der Loo, Big Data (and official statistics) Working paper prepared for the Meeting on the Management of Statistical Information Systems. (23-25 April 2013)
[26] Rebecca Tave Gluskin and others. Evaluation of Internet-Based Dengue Query Data: Google Dengue Trends. (PLOS Neglected Tropical Diseases, 27 February 2014)
[27] Emilio Zagheni and others. Inferring international and internal migration patterns from Twitter data. (World Wide Web Conference, April 7-11, 2014, Seoul, Korea)
[28] New primer on mobile phone network data for development. (UN Global Pulse, 5 November 2013)
[29] Joshua Blumenstock and others. Motives for mobile phone-based giving: evidence in the aftermath of natural disasters (30 December, 2013)
[30] Michael Wu. Big Data Reduction 3: from descriptive to prescriptive. (Science of Social blog, Lithium 10 April 2013)
[31] Arvind Narayanan and Vitaly Shmatikov Robust de-anonymization of large sparse datasets. Pages 111-125 in Proceedings of the 2008 IEEE Symposium on Security and Privacy (IEEE Computer Society Washington, DC, USA 2008)
[32] Yves-Alexandre de Montjoye and others. Unique in the Crowd: The privacy bounds of human mobility (Nature scientific reports 25 March 2013)
[33] Erica Goode. Sending the police before there’s a crime. (The New York Times, 15 August 2011)
[34] It is getting easier to foresee wrongdoing and spot likely wrongdoers (The Economist, 18 July 2013)
[35] Kate Crawford. Think again: Big Data. Why the rise of machines isn’t all it’s cracked up to be. (Foreign Policy, 9 May 2013)
[36] Neil M. Richards and Jonathan H. King. Three paradoxes of Big Data. (Stanford Law Review, 3 September 2013)
[37] Neil M. Richards and Jonathan H. King. Big Data ethics. (Wake Forest Law Review, 23 January 2014)
[38] Neil M. Richards and Jonathan H. King. Gigabytes gone wild. (Aljazeera America, 2 March 2014)
[39] Rahul Bhargava. Toward a concept of popular data. (MIT Center for Civic Media, 18 November 2013)
[40] James Manyika and others. Open data: unlocking innovation and performance with liquid information (McKinsey Global Institute, October 2013)
[41] Emmanuel Letouzé. The Big Data revolution should be about knowledge security (Post-2015.org, 1 April 2014)
Más sobre Datos